

Ghideon
Senior Members
-
Joined
Everything posted by Ghideon
-
Can you elaborate? Regarding the original question; I did a quick search and I am unable to find consensus. Some papers argue that musical ratios such as octaves are connected to physical properties of the human ear, example: https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0037988 But other papers argue that perceptions of musical octaves are learned: https://www.quantamagazine.org/perceptions-of-musical-octaves-are-learned-not-wired-in-the-brain-20191030/ Link to paper: https://www.cell.com/current-biology/fulltext/S0960-9822(19)31036-X
-
So does that mean that you claim that for an observer in the vacuum of space the sky looks completely black? The sun and stars are only visible if the light is reflected off a mirror?
-
You seem to use some non standard definition of "reflected"? How would detection of photons require a reflection?
-
Good point. They may also try to affect searches; an algorithm could possibly rank an issue that was resolved higher than a something that the algorithm considers to be an open discussion.
-
Have you ever looked at a fire, a computer screen or stars? Do you see them because of reflection of light?
-
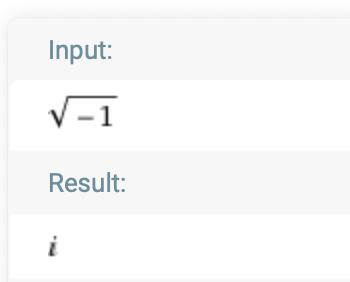
I tried WolframaAlpha and the result seems mathematically correct: i is the symbol used to denote the principal square root of -1, also called the imaginary unit. (from WolframAlpha's description) You can also search for "i" on WolframAlpha read more about the definition. Here is a direct link: https://www.wolframalpha.com/input/?i=i&assumption={"C"%2C+"i"}+->+{"MathWorld"}
-
Solar activity. According to wikipedia attempts to correlate weather and solar activity have had limited success but it may still be useful as a starting point in a work of fiction. https://en.wikipedia.org/wiki/Solar_cycle You could change the 11 years to four years and make it have more impact on the planet. There are papers discussing connection between the 11-year cycle and for instance tree-rings. So in my opinion it would not be too unscientific have a fiction solar system where harsh winters occur due to solar cycle. https://en.wikipedia.org/wiki/Solar_cycle#cite_note-Luthardt2017-10
-
You are correct. I did not intend to argue that the force never exceeds the static value, sorry if my post was not clear on that.
-
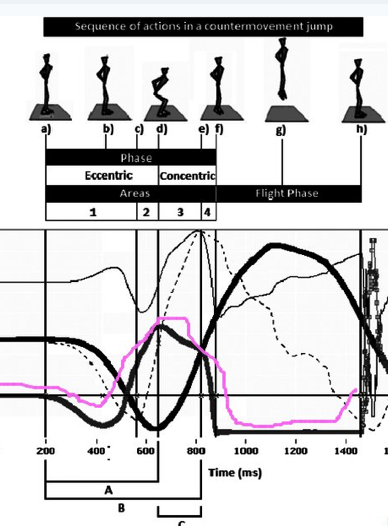
My point is: when during the attempt did they record dip? I did as well, thanks for your comment that made me look again. I now draw the conclusion that the scale is reduced below that of the weight a second time possibly matching @studiot's observation(?). First time is at approximately from a to c, while bending knees to prepare as mentioned before. Second time is near point f just before leaving the scale on the way up. Assume the individual would not actually jump but instead reduce their force just so that they end up standing on tiptoe. Then the flat segment would show the static value (the mass of the individual) at some point slightly later than f. I tried myself and unfortunately my digital bathroom scale locks the value once a static value is reached. My scale is not affected by movement once it has performed a measurement, I need to step off and wait for it to "reset". This has no impact on others observations, I'm just noting that bathroom scales seems to be constructed to behave rather differently under the dynamic conditions described in this topic.
-
Please have a look at my attempt at explaining the researchers recording. My interpretation is that the scale reading is low while the body is moving down ("A" in picture). The individual in the measurement bends their knees fast and that results in a low force pressing the scale.
-
@studiot Thanks for adding science to the thread. Letters a-h are from your image: a: standing with straight legs without movement. Reading of scale is constant since body is at rest. b: Bending knees. While doing this the centre of mass of body is initially accelerating down; any force from the scale acting on the body is less than the weight of the body. Scale is reading less than mass of body. b-c: tightening of leg muscles stops acceleration down to have the body stationary with bent legs. While the body decelerating the scale reads more than the mass m. c : starting the upwards push. There is no flat segment of the curve so the body is not at rest with bent legs for any extended amount of time. d: beginning to push/straighten legs to jump. e: (approximately) heels leaves the scale since legs are straight, pushing with calves muscles; force is lower than while using upper leg muscles. f: the body is airborne. h: landing There is a brief moment e-f where the scale would read less than the body mass while the body is standing on toes. The body is not at rest relative the scale during that period of time. I am not an expert, my interpretation may be completely incorrect.
-
In the context of this thread I believe that Newton mechanics and specifically F=mg will predict what happens when a mass m is put on a typical household scale. Flesh or wood or bones or quick silver or gravestone or whatever will not have an effect*, Newtonian physics is applicable in this case. OP seems to argue that Newtonian physics fails to predict the force if the mass m consists of flesh. I fail to find any evidence in this thread or in any mainstream physics supporting that opinion. (Disclaimer: Of course not counting engineering limitations, using the scale outside of limits, not keeping the mass stable or other out of context reasons.)
-
You might want to use the quote function. The above looks like a support for awaterpon's claims, was that the intention? Can you elaborate; how does what you describe result in awaterpon's claims flesh (and bones) and physics?
-
What are the properties of flesh (and bones), according to your idea, that makes the difference?
-
Let's try something else. What objects can replace the word "human" in your definition and still give exactly the same results as you claim? Can "human" be replaced by "dog", "humanoid robot" or something else?
-
It seems like I do not share that view. I was curious about the posted idea and how someone would draw such conclusions about electromagnetism and as expected this thread contains no support for new scientific progress. But it was a good excuse to return to some books I have not touched for a while. (edit: I just found out that Bill Hayt and John Buck's Engineering Electromagnetics is updated and still in print)
-
You are wrong and you have stopped to say anything about physics so its just the relocation left. Which island have you selected? I asked for something supporting your claims or clarifying possible misunderstandings. The formulas and laws of physics in my books on electromechanical engineering seems to disagree with your statements and pictures.
-
What theoretical model and experimental results would you like me to present as motivation? It seems reasonable to assume some motivation is required (those invited to propose nominees are sent confidential nomination forms* so full insight is not available to me at this point). Also note that the rules for the Nobel Prize in Physics require that the significance of achievements being recognised has been "tested by time"; "deserving a Nobel prize" means my trip will take place approximately 2041 or later. *)https://en.wikipedia.org/wiki/Nobel_Prize_in_Physics#Nomination_and_selection
-
Your claims and explanations seems to be in disagreement with current mainstream physics, so a supporting reference would have been helpful. That would require (a lot) more evidence than presented so far.
-
I would like to see a rigorous definition of "alternative weight" "alternative mass".
-
Can you provide a reference?
-
Let's try another point: "effortless" walking is a psychological effect, not physics, in this case. An experience of "effortless" walking is not an indicator that mass magically is reduced. An example of your flawed logic: Assume a well trained human A runs "effortlessly" at the same speed as a not so well trained human B. A and B has the same mass. The fact that B struggles to keep up with A does not mean that B have some unspecified "alternative mass", A and B have the same mass. B's struggle is more likely due to being less fit than A. Another example: After 10km of running I do not run effortless anymore. How much "alternative weight" have I gained according to your idea? Have you investigated the possibility that human experience "less effort" because human benefits from not having to feel like walking requires a lot of effort?
-
Today I learned about "tall poppy syndrome". According to Wikipedia*: Thanks @beecee Maybe related to (but not the same as) Law of Jante** ? I need to do some reading. *) https://en.wikipedia.org/wiki/Tall_poppy_syndrome **) https://en.wikipedia.org/wiki/Law_of_Jante
-
That got me thinking; maybe this helps OP: In the video below the lecturer finds the force exerted on the Achilles tendon when a person is standing on tip-toes. The video will guide you through a simple model of the foot and lower leg and apply basic mathematics and physics. Talking of archimedes; maybe OP can try standing on toe partially submerged in water and report back....
-
My main problem with this specific debate is the incoherent questions, unsupported claims and undefined concepts... ... add conspiracy tales to the list of issues.
