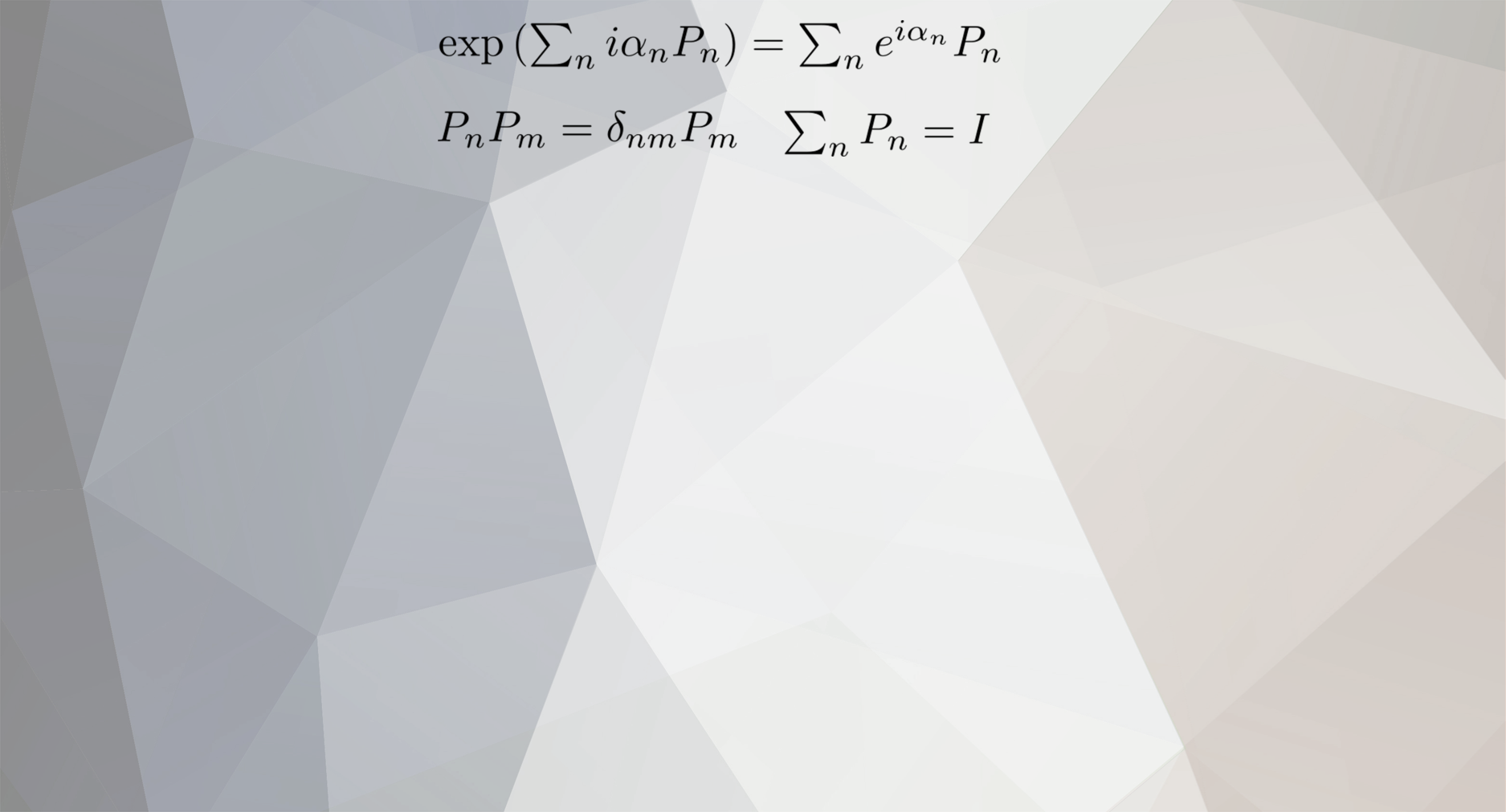

joigus
Senior Members
-
Joined
Everything posted by joigus
-
He probably meant "the idea of God", if we are careful with the use-mention distinction. But I think he either 1) Was a distinguished idiot; or 2) Was insightful in such a bizarre way that mostly idiots thought they understood him. I personally didn't get much from his philosophy, I must say.
-
Nietzsche didn't propose to replace God. He proposed that God is dead! An AI should only be as good as what it eats. So we'd better feed them well. That's more Feuerbach than Nietzsche.
-
Both in mathematics and physics it seems to be happening to some extent. It's been a while since the problem of classifying all finite, simple groups was cracked in its final steps by (non-AI) software, so I think it's been a long time coming. Machines were instrumental in classifying the 26 isolated oddities (the so-called sporadic groups), and that was back in 1983. It's perhaps worth noticing that the proof was later considered wanting and it was finally clinched by humans in 2004. I still think that the process relies very heavily on clueing in the machine, as well as it does on humans assesing what the former is saying. I don't think the next vital, perpendicular thinking process will come from AI, though. It's probably gonna be more like 'will you check this for me while I get some sleep?' Let's all hope it will remain that way.
-
As a matter of fact, I don't think the OP actually even understands what mathematics is really about. It's not about predicting events that may or may not happen. It's rather about logical structures that are possible in a space of logical premises. Whether something will or will not happen is not a subject of mathematics. That's rather a subject of engineering, physics, the theory of dynamical systems at large (economy, populations, etc.), chemistry, and the like. So there's a fundamental mismatch in the premise, I think.
-
Absolutely. There's nothing in a year that's not to do with this part of the galaxy. But there's much in a month that is to do with being Babilonian.
-
Describe they do. The question is whether they do it correctly, with some actual correlation between them and the event and features they purport to describe. They don't.
-
This is what I understood by 'numerology': https://www.oxfordlearnersdictionaries.com/definition/english/numerology?q=numerology No cause and effect, no reasonable connection, no definitions, propositions, lemmas, theorems and corolaries. No (A) implies (B), (A) if and only if (B), no principle of induction, no demonstration... Nothing of that. 'Reading' the entrails of animals is no part of zoology or anatomy either.
-
Why would what , at best, is a pervesion of standard mathematics be a part of standard mathematics?
-
-
Not taking a dive in a pool because there's, say, 10⁻¹⁰ chance of finding a shark in it, is not a grown-up concern IMO. It's more akin to night terrors. This is like not taking a dive in a pool because there's 10⁻¹⁰ chance of finding a shark in it.
-
I needed to highlight these two comments and sub-comments of them, as I think they're so close to the essence of what the problem might be if AI is given too much leeway in telling us what's next. Assigning statistical weights to conjectures, answers to hard questions, and the like, relies very heavily on previous answers to (as well as posing of) similar questions, never getting us necessarily anywhere closer to unexpected avenues of inquiry or further questions, or counter-arguments.
-
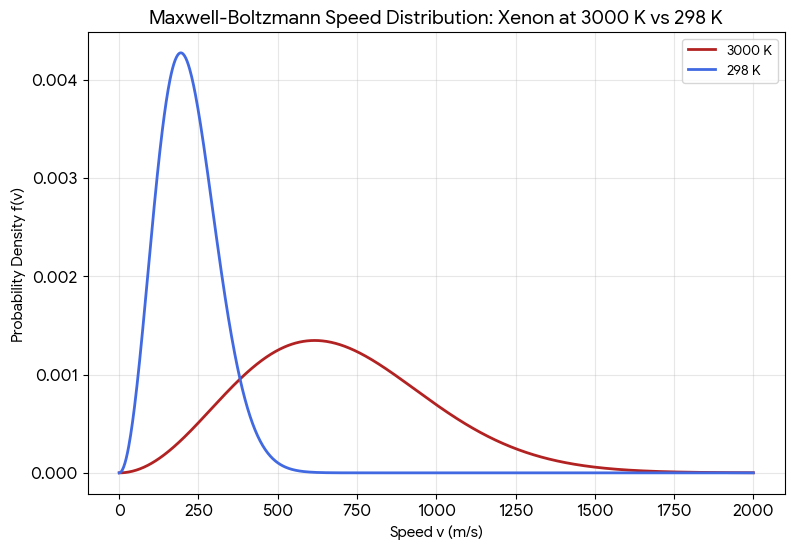
This kind of thinking has a tendency to snowball that, as I remember, reached a peak somewhere around 2008, bordering into horror-sci-fi: https://cerncourier.com/a/the-day-the-world-switched-on-to-particle-physics/ I remember arguments both from theory (evaporation of black holes) and experiment (existence of high-energy particles from cosmic rays) putting the matter to rest.Depends on how you define a reality. It would be essentially different from 'red, blue, and green' reality if we have to make room for quantum mechanics of spin. But that would take us off on a tangent.I think you're getting confused here. Space itself is not of a statistical nature. Things going on in space are. Space is just a backcloth of everything else. You cannot set up a proper statistical question that involves only space with nothing in it. Wally can be here or Wally can be there. But there's nothing to be done with here and there without some kind of Wally.Ok. I must say I'm quite less sophisticated when it comes to probability that you probably picture me to be, and you yourself are. The cases you comment of disqualified horses, dead heats, etc, IMO, would be completely smoothed out to zero by means of the 'frequentist approach': They almost never happen. The way I always understood probabilities is: You first make a hypothesis based on symmetries, known features, engineering specs and so on, direct exploration, etc. Then you do thousands upon thousands of experiments and apply the 'frequency test'. That way, you see whether your statistical hypothesis was correct. In some cases, like physics, you have physical principles that allow you to not guess in the total dark. In your horse-race example, your hypothesis would be based on a priori conditions on the horses: Their physique, breed, biometrics, and so on. Then you would have them race with different riders, atmospheric conditions, etc. Something like that. I think it's fair to say Bayesian methods give you equal probabilities at first, but that's precisely because the first-order approach is to assume no bias, and then correct your hypothesis as you learn more about the different odds (the heart and soul of Bayesian methods or, as I like to say, probe more and more deeply into the sample space). So the first assignment of probabilities doesn't give you any better insight than the other ones. I think you're right in your conclusion. But I don't think it's because infinity has limits. I think it's because infinity is not a number, it's more of a topological nature (the boundary of all numbers), so you cannot reach it numerically, which is quite the opposite of what you said in words, even if your intuition might have been right.Yes. https://en.wikipedia.org/wiki/Frequentist_probability No. Please, explain.Just today, I was fumbling for the word 'tetration' as a binary operation. Thank you.In response to your first question: Yes, that's exactly what I mean by a frequentist definition. In response to your second question: I assume by 'my scenario' you mean the molecule-speed vs probability scenario...? In that case, F as absolute frequency (number of times it produced a certain value) would be, say, 1 or two, while the number of times it's been tried would be (ideally) infinitely many. And therefore, the relative frequency would be f = 1 or 2 / infinity = zero. => zero probability does not imply zero occurrences when infinitely many tries are involved. I hope we're talking about the same thing. If not, it's probably my fault, and I apologise. Please, point out to me, if you can, where you made this qualification, as it escaped me. It's a very interesting point to me, as I think many misunderstandings when talking odds come from this, as 'random' could mean Laplace (finite sample space), binomial, Poisson, Gaussian, or who knows what...Therefore I should have said 'at T=3000K the Xenon molecule is much more random (much less predictable) than at T=298k. I hope I didn't make my argument completely un-understandable. Sorry. I sometimes think I may well have been misdiagnosed as 'cognitively normal' when I may well belong in the 'cognitively-exceptional' spectrum. For some uncanny reason, I tend to express thing the opposite way I mean to.Yes. Context means a lot for us humans. You were right to say it's not a tool for the masses. I've recently thought of this metaphor: AI, if used properly, should become some kind of pseudopodium stemming from our intelligence, not a prosthesis of it. Unfortunately we see too many examples of the latter, and too few of the first.Yes, but simply declaring 'lack of information' doesn't determine the probability distribution, does it? Did you happen to take a look at Bertrand's circle paradox? In the case you provide, a relatively-simple change of variables to a certain s=f(pi) renders the probability distribution deterministic in s. If you're not given this information, every digit has equal probability of occurring (as far as we know, because nobody can decode pi in terms of digits), so it's a good generator for the prescription 'equal probability for every digit from 0 to 9). I draw your attention on the fact that 'equal probability for every digit from 0 to 9' is just one way of defining 'random' in this context. Yes, but (I insist) 'random' by itself doesn't mean much. Here's the distribution of probabilities for the speed of a Xenon molecule at temperatures, T = 298 K and T = 3000 K. Both are random, and yet, at T = 3000 K the Xenon-molecule speed is much less random (much more predictable) than at T = 298 K: I should have said 'much more random'. Sorry.
 You have to work a lot on your prompt, and diagnose mistakes like these to rephrase your next prompt. And I would add, never venture into concepts that you know even the experts have not reached an agreement on. Machines lack context, while we are context machines. A simple question like, 'how old are you?' could be understood to mean 'how long have you as an individual been around?' or 'how long have you humans been around?'The infinite-monkeys is a metaphor to illustrate the arguably paradoxical nature of probability. In that case, you take an extremely unlikely event and flood your laboratory with attempts to obtain a succesful outcome. What paradox does it try to illustrate? That, in the limit, even an event with probability =0 is possible if there is a continuum of outcomes accesible. The metaphor makes the point clear even though no-matter-how-big a number of monkeys will never produce a continuum of outcomes (books written at random). But that has little to do with what I was trying to argue. Namely: That the word 'random' doesn't necessarily mean something precise in a number of cases.Maybe so, but not by a humorous observation on the nature of our expectations. 'Everything that can go wrong will go wrong' is no probabilistic law. Starting with: it's manifestly false. The nature of our expectations is quite irrelevant to the laws of probability anyway...
You have to work a lot on your prompt, and diagnose mistakes like these to rephrase your next prompt. And I would add, never venture into concepts that you know even the experts have not reached an agreement on. Machines lack context, while we are context machines. A simple question like, 'how old are you?' could be understood to mean 'how long have you as an individual been around?' or 'how long have you humans been around?'The infinite-monkeys is a metaphor to illustrate the arguably paradoxical nature of probability. In that case, you take an extremely unlikely event and flood your laboratory with attempts to obtain a succesful outcome. What paradox does it try to illustrate? That, in the limit, even an event with probability =0 is possible if there is a continuum of outcomes accesible. The metaphor makes the point clear even though no-matter-how-big a number of monkeys will never produce a continuum of outcomes (books written at random). But that has little to do with what I was trying to argue. Namely: That the word 'random' doesn't necessarily mean something precise in a number of cases.Maybe so, but not by a humorous observation on the nature of our expectations. 'Everything that can go wrong will go wrong' is no probabilistic law. Starting with: it's manifestly false. The nature of our expectations is quite irrelevant to the laws of probability anyway...

Important Information
We have placed cookies on your device to help make this website better. You can adjust your cookie settings, otherwise we'll assume you're okay to continue.