

Ghideon
Senior Members
-
Joined
Everything posted by Ghideon
-
multiplication does not add information about 11. Did you mean "division" instad of multiplication? As far as I know it is harder. Primality testing (is N prime?) algorithms outperforms best algorithms for semiprimality testing (is N the product of exactly two primes?) as far as I know.
-
That sentence seems kind of odd? This is the first time you mention Twin Primes so I do not know how it is related to previous discussion. Yes, it follows form elementary modular arithmetics? I might be able to produce a mathematical proof if it's helpful.
-
Have you compared your ideas with observations such as GW170817? the merger happened 140 million light years away. https://dcc.ligo.org/public/0145/P1700294/007/ApJL-MMAP-171017.pdf
-
Here are some illustrations of a sieve algoritm visualised in a grid with 6 columns. First the final result: natural numbers n<300 with primes marked in green. The list of primes is the result of running the sieve of Eratosthenes for n<300. Illustration of the starting point of the algorithm; we use grid cells without numbers for this illustration. We will run the standard algorithm by counting the grid cells and count how many cells to skip rather than looking at numbers in the grid. Count grid cells from top left (first cell = 0) and mark every second cell with a count > 2. I guess this could qualify as a "pattern" since it forms coloured stripes of marked cells? Note again that this is basically sieve of Eratosthenes, just without any optimisations. Nothing special. Start from the beginning and count past the blue bordered cell until an unmarked cell is found. You will count 0,1,2,3. Mark every 3rd cell after cell no 3. We now have two unmarked columns. If the cells were numbered these cells would cover the all numbers 6k+1 and 6k-1 used in a 2,3 wheel. Again this is standard except for the start; we would skip ahead to p2 (cell 32=9 in this case) in the standard algorithm Note! the illustration is unclear; The blue border around cell 2 has disappeared. Starting from the top again: first empty cell after the previous blue framed one is 5. This time, when we count cells 5,10,15,... it looks like some kind of diagonals. Note that we revisit some grid cells; I mark them again to show that some kind of "pattern" appears. If we continue like there will be alternating "patterns" that becomes sparser as the count of the starting cell grows. The final result before we put numbers in the cells. By numbering from top left starting with 0 every white cell will contain primes and every pink cell will contain composite numbers.This is of course nothing new or any patterns in prime numbers, it's just a consequence of expressing the well known sieve an visualising in a grid. This is how I see a connection between the sieve of Eratosthenes, wheel optimisation and what someone may see as "patterns" during the execution of the algorithm. As a reference; the complete set of illustrations in an animation. Note that without any optimisation we do not cut off at sort(n) meaning there is a lot of unnecessary work in later steps. I kept these as an illustration. In the end of the animation the numbers with primes highlighted will flash by before restarting. See the first picture above for a freeze of that frame. It was a little tricky to get this right, hopefully there are no major mistakes.
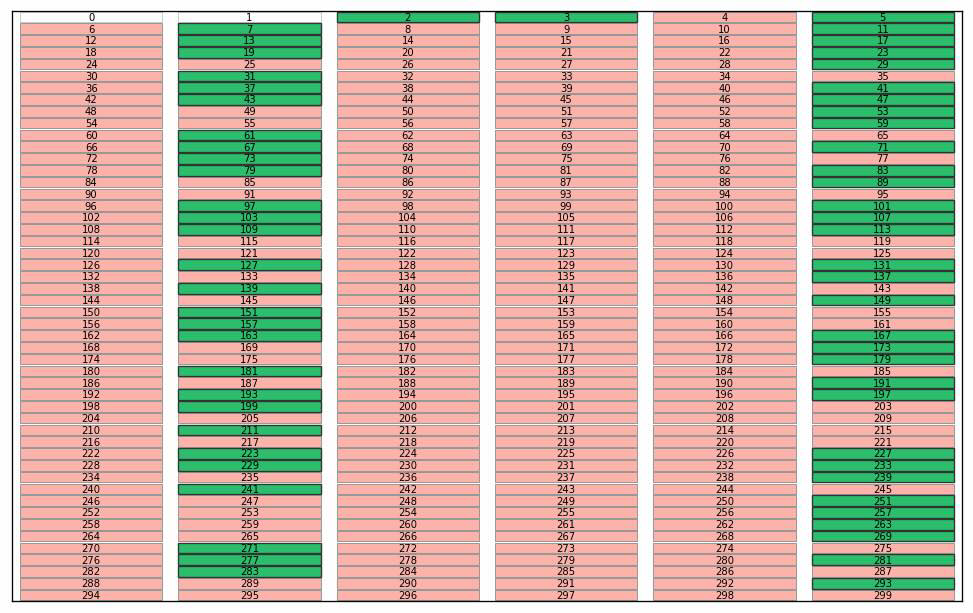
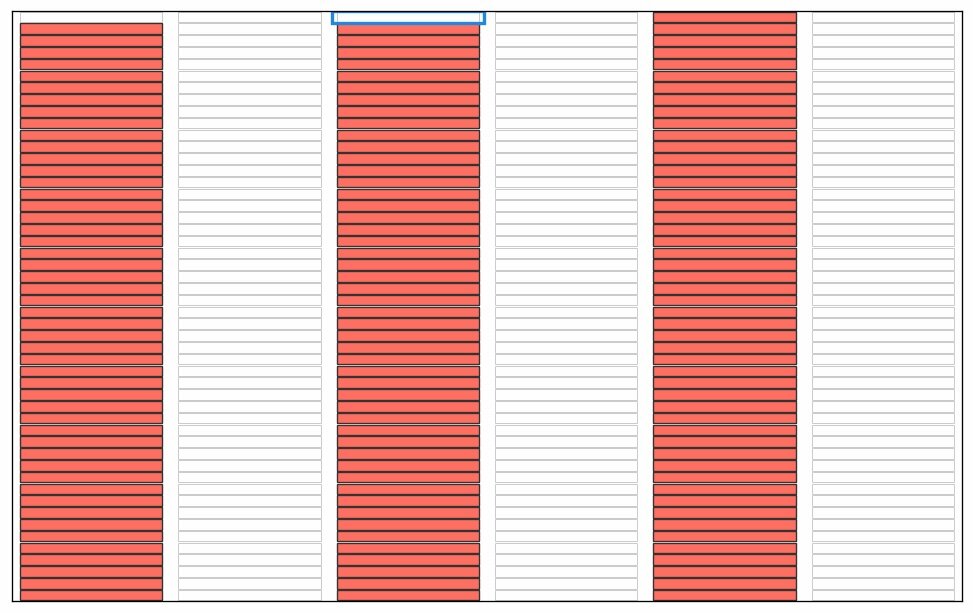
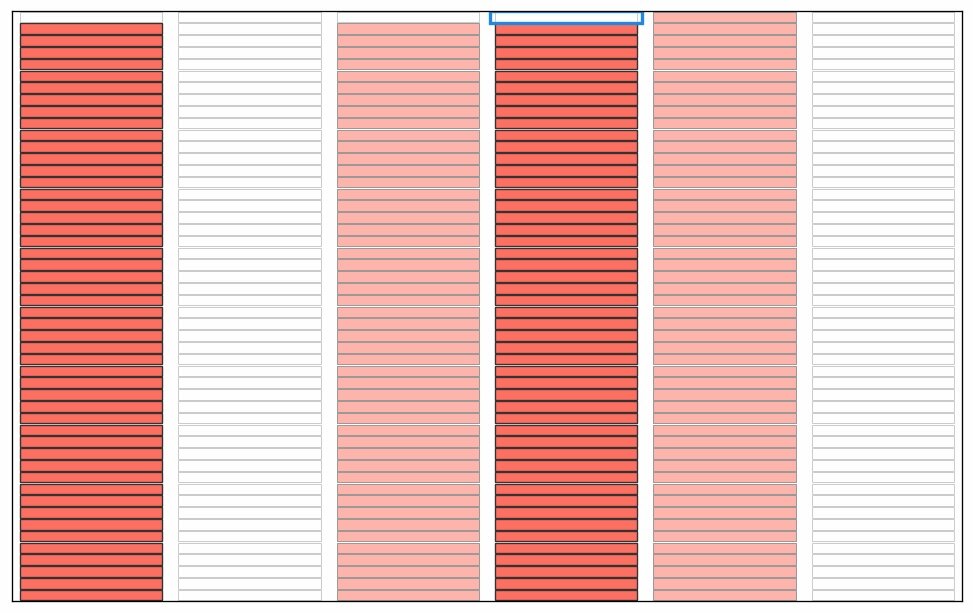
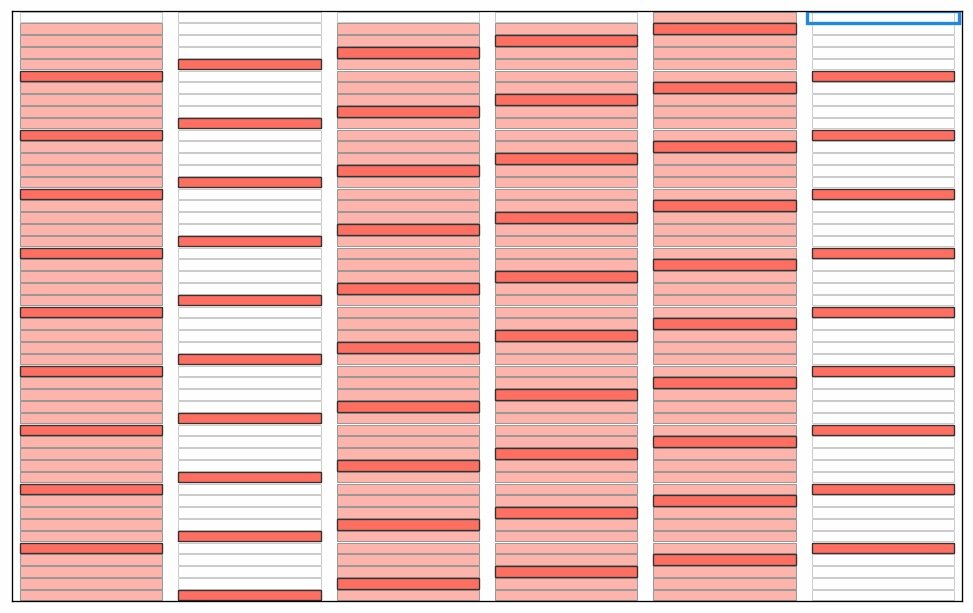
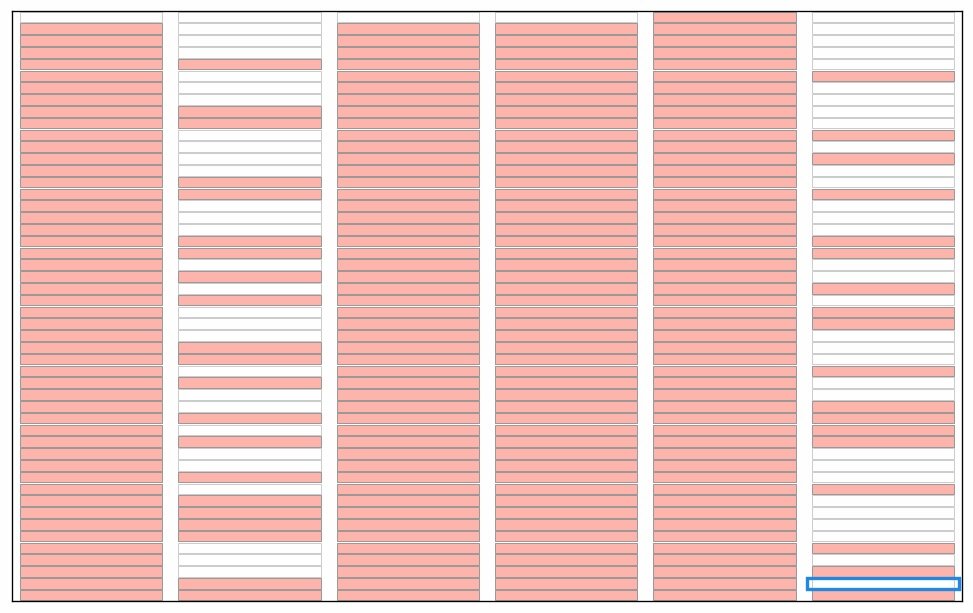
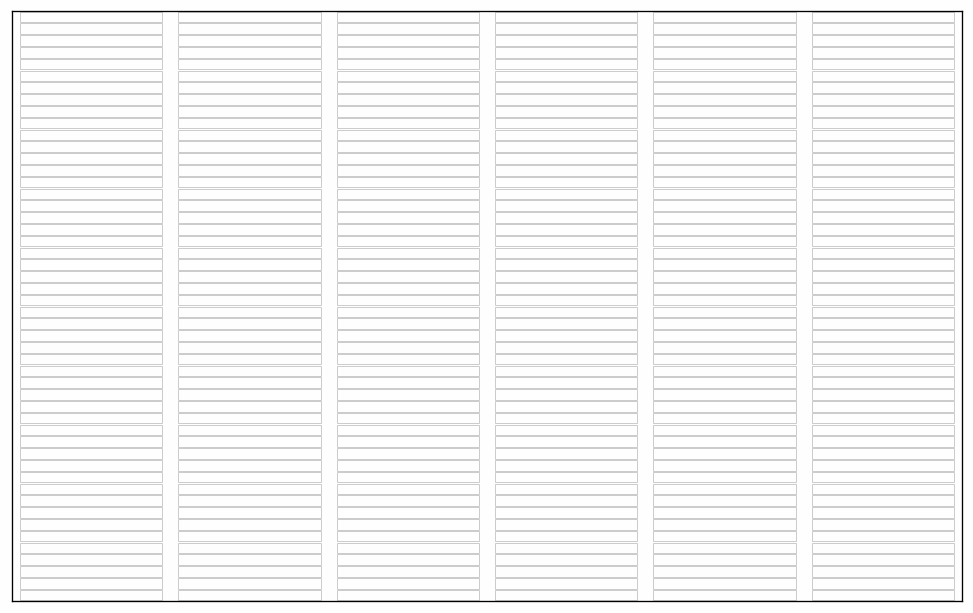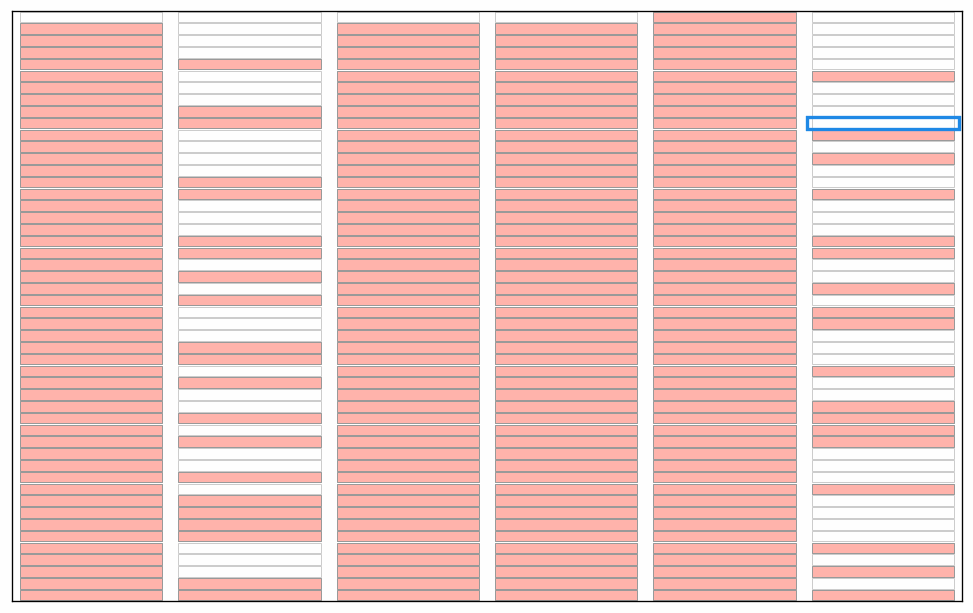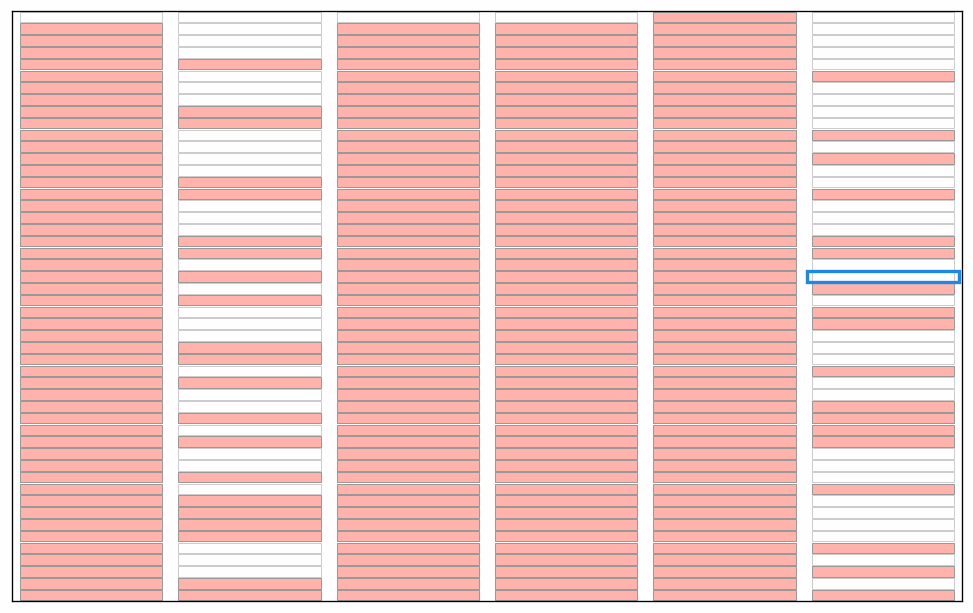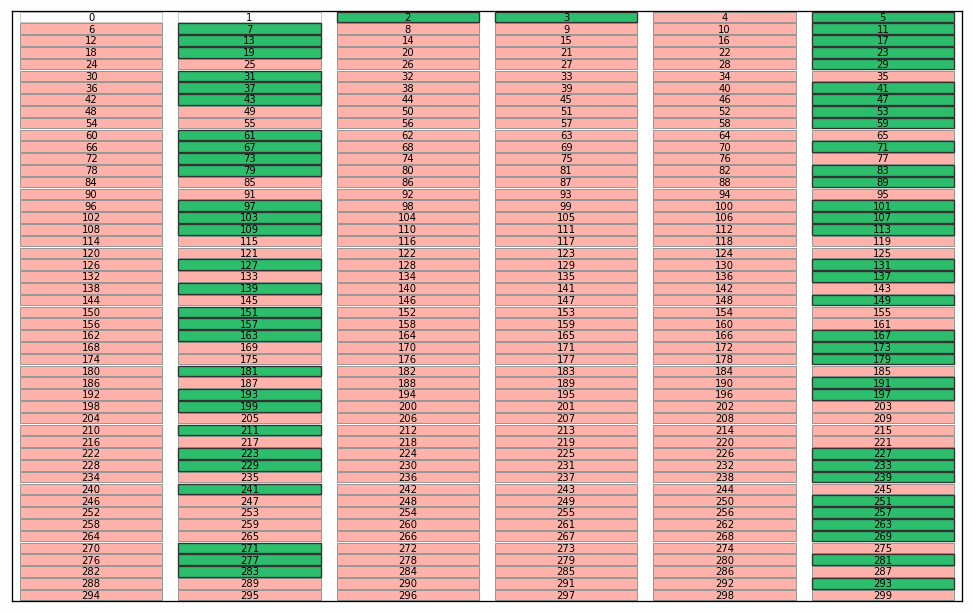
-
d The program does not seem complete but it helps; it still looks like the classic Sieve of Eratosthenes + optimisation. I thought about this; let's analyse from a different angle. A sieve is a step-by-step procedure systematically crossing out composite numbers. You don’t have to “test” each number for primality but loop over small primes and mark their multiples. For example, when on p=5, marking 10,15,20,25,… only hits composites; same idea for p=7,11,… Each pass begins from the next unmarked integer; in a sieve that guarantees its prime (if it were composite, a smaller prime factor would already have crossed it out). This is the basic idea of the classic Sieve of Eratosthenes as far as I know (without any optimisations that seems to be part of the idea in OP). But now; if the implement the the classic Sieve of Eratosthenes, and just look at the output. I mean how Sieve of Eratosthenes graphically looks like; is there anything that looks like "patterns"? And if so, are these "patterns" what you use in your idea? If this long-shot is correct then we may be looking at the same algorithm but from different angles; you are reverse engineering the Sieve of Eratosthenes from observation of what it "looks like". I might try to create an illustration of this.
-
The idea is about sieving; you mark all non primes in a list of integers 0..n which leaves you with a list of the prime numbers <= n. In a sieve approach you do not test a number for primality, you remove non-primes by some algorithm until you have only prime numbers.
-
Ok; to avoid further contradictions in your descriptions, maybe start form scratch: Describe the algorithm of your sieve idea. Be detailed so that someone that does not yet know your idea can follow the algorithm and check that it produces a list of prime numbers smaller than some natural number "n". This could be performed with pen and paper (for small n) or programmed for larger values of n. Once the algorithm is clearly described we can see if it works for any n, if it is identical or similar to known methods and, if interesting, analyse time and memory complexity.
-
That is one use of wheel factorisation. If you scroll down on the wikipedia page* you will find: Trial division is of less importance in this discussion; you have asked about a sieve idea of yours. That seems to contradict what you have described so far; your opening post states that you use the set of values: Which means that you work with numbers co-prime to 6. Also, you refer to a set of values to mark non-primes: You still have not commented on O(n log log n) time with O(n) space; have you compared your algorithm to wheel optimization and Eratosthenes sieve; the one I compare to your description of your idea? If you do not know how to compare, just post a question. https://en.m.wikipedia.org/wiki/Wheel_factorization
-
I don’t see any follow-up in my comment on complexity: @bdonelson are you familiar with this kind of notation and it’s connection to your description? What do you mean by testing?
-
Ok. I did not compare your description with trial division. You may want to look at wheel optimization and Eratosthenes sieve, the one I mentioned.
-
Thanks for the update. What you describe still looks like 6-wheel optimization of the Sieve of Eratosthenes, nothing different. That reduces constants by skipping multiples of 2 and 3 but doesn’t change the asymptotics; the standard sieve runs in O(n log log n) time with O(n) space* and your description doesn’t indicate an improvement beyond that. *) unsegmented
-
Unfortunately I don't understand the description of your method so I can't comment on its complexity.
-
Sieve of Eratosthenes, the one I mentioned above, use additions. No division or multiplication is needed. (Note: just as @studiot I am not a number theory specialist. I have some limited knowledge and interest in primes mainly due to it's use in cryptography)
-
Thanks for the answer. It appears equivalent to a 6-wheel optimization of the Sieve of Eratosthenes rather than a new sieve. Unfortunately the current description is too vague to be further analysed.
-
Can you explain the pattern? I do not follow how it works. In other words, assume I have a fair amount of computing power available; what should I implement in software to beat able to test your idea up to some large number N. I know how to program but I do not have a clear specification of your new prime number sieve idea.
-
According to who or what? A reference would be appropriate; your comment is not based on writings I am able to find in the bible*. *) with my rather limited knowledge about this topic
-
Isn’t that a claim of the opposite of what is in the Bible texts in Cristian belief system? Monotheism; people should not worship the moon? Extract from an online Bible: Deuteronomy 4:19 “And when you look up to the sky and see the sun, the moon and the stars—all the heavenly array—do not be enticed into bowing down to them and worshiping things the Lord your God has apportioned to all the nations under heaven.”
-
Due to the rising usage of chat bots and "AI" backed by Large Language Models i hereby suggest the following to be added to the dictionary: Tensorology A belief system that attributes mystical, consciousness, or cognitive significance to multidimensional sets of numbers and their relationships with events and people. In modern contexts typically refers to interpretations in which such numbers are associated with Artificial Intelligence and more specifically with the static weights of LLMs (Large Language Models). The study or practice of attributing meaning to the numerical structures of machine learning models. Distinguished by internal divisions between major factions of practitioners, notably: Promptologists who emphasize the role of prompt structure in producing machine consciousness and Layerologists who focus on the internal numeric representations of models and mystical attributes. Note: Numerology is closely related and may be regarded as the special case of this belief system in which the focus is on scalars or lists of numbers. The following concepts are still under investigation and lack formal definitions; require further study before any formal proposals can be advanced: Narcaissism - AI boosted narcissism. Narchissism - An AI ethics subfield; human induced machine narcissism where an LLM, due to sustained human input, generates text exhibiting simulated narcissistic tendencies. Dunning Kruger Loop - feedback loop where user and chatbot convinces each other about their great discoveries of previously unknown scientific theories, typically in theoretical physics. Hallhumanisation - When a chatbot user due to ignorance "hallucinates" concepts and theories not supported by mainstream science and hereby tricks an LLM into producing scientific-looking but false output (this false output is also known as "hallucination").
-
The LLM is immutable. There is no session, memory, state, history or any kind of learning involved when using an LLM for inference. Demonstration* where I interact with an LLM with "as little software as possible" wrapping it: ("user"=my prompts, "assistant"=response generated by LLM) user: hello, my name is Ghideon. assistant: Hello Ghideon! It's nice to meet you. Is there something I can help you with or would you like to chat for a bit? user: Can you tell me something cool about my name, related to cartoons? assistant: I 'd love to try! Unfortunately, I don 't know your name. Could you please share it with me? Once I have your name, I can try to dig up some fun and interesting facts about it related to cartoons! So what happened here? With my first prompt as an input the LLM is used to generate the response starting with "Hello Ghideon!" I then sent a second prompt and as expected the LLM does not generate any content related to my first prompt; there is no state in the LLM. But how does it work then; a typical chatbot will provide an answer that takes my first prompt into account? What happens behind the scenes in the software between the user and the LLM? The software sends the complete history, including previous output of the LLM, into the LLM. The result is that the LLM produces some text that according its training statistically matches the next step in a dialogue. In the case the second input to the LLM looks something like this**: "messages": [ { "role": "user", "content": "hello, my name is Ghideon." }, { "role": "assistant", "content": "Hello Ghideon! It's nice to meet you. Is there something I can help you with or would you like to chat for a bit?" }, { "role": "user", "content": "Can you tell me something cool about my name, related to cartoons?." }The above obviously gets longer and longer. Depending on models the context window can be small or large and taken into account when managing the LLM, for instance deciding if a sliding window is to be used, or other strategies for reducing the length of the history without loosing important parts. Hope the above example helps illustrate why I believe it is of importance to understand what you have a hypothesis about; properties of an LLM? LLM+some software? Or the behaviour of an organisation that operates a software service and possibly uses chat histories in the training of new models? (or something else?) *) Technical notes: The following can be used for reproducing: Ollama 0.11.2 running on MacBook Pro, model llama3.1 (91ab477bec9d), temperature=0, seed=42, endpoint: /api/chat. For easier reading I have removed the JSON formatting and control charcters from the dialogue. In this simple example I did not use a reasoning model but that would not change the fact that the LLM is stateless. I use a local installation for full control of the setup. OpenAI has a generally available API online; the "messages" section in their completion-api serves the same purpose as the "messages" in the interaction with Ollama above. **) part of JSON structure from a call to Ollama API; only parts needed for illustration included.
-
1: how do you access "ChatGPT5"? (OpenAI has as far as I know not released a version 5 of their models yet) 2: what does "ChatGPT5" mean here? A service, a model, other? (I have seen this name in use for services that seem to be from parties that are not OpenAI*) *) I'm avoiding links to external sites unless asked.
-
Thanks! Then I have enough understanding of the setup to comment on: An LLM, AI (generative AI or any other kind currently available) is obviously not conscious so I don't see any connection to "consciousness" when discussing the hardware and software (in any combination AI or other). So dropping that question is a good move since the answer is trivially "no". As for the hypothesis I'm not sure what you are looking for here: 1: We know that the LLM is immutable when used for inference in for instance a chatbot; by definition the user prompts used as input to the LLM does not change the model. So there is no need to form a hypothesis or test since the answer trivial; prompting does not change an LLM; no matter how intricate or advanced prompts are. 2: One purpose of generative AI and the usage of LLM is to generate output* that mimics text a human could produce, and to do so based on user input. So of course the output of the LLM is influenced by the user's input. (This is an area of ongoing research for instance if impolite prompts result in poor performance or not) So the question is: what do you wish to form a hypothesis about? It can be the LLM in isolation, the complete system such as a publicly available chatbot service, or some other alternative. In the case of a chatbot there are mechanisms outside of the LLM that needs to be considered. For instance the system prompt has impact on how the users's conversational style influences the output of the LLM. Some notes about testing where the above distinction makes a difference: If the hypothesis is about LLMs we can run tests on one or more of the available open models in an environment where we have full control of all parameters (random number seed, system prompts, temperature, repetition penalty, ...) If the hypothesis is about a product or service we (most likely) do not have access to the system prompt and other mechanisms between the user and the LLM. Here tests will be a little more "black box" and maybe more related to jailbreaking** than parameter settings. Reproducing a test result may not be possible due to updates of the service or simply by the lack of access to random number seeds and temperature settings. Hope this makes sense, otherwise feel free to ask for clarifications. *) @TheVat provided a good summary above; no need to repeat **) Tricking or manipulating a large language model (LLM) chatbot into producing responses that it is normally programmed to avoid, often by circumventing built-in safety filters and ethical guidelines. This may not be allowed by license agreements and vendors will typically update software to prevent known issues.
-
That site seems based on OpenAI's GPT-4 architecture Ok! Do you use a predefined set of prompts? Or does the prompting (and hence the effect) depend on the human interpretation and prompting?
-
Just so I address this correctly; is the following hypothesis still something you wish to test using an LLM? Or is the above replaced by; Is the hypothesis about a specific LLM? LLMs with some specified properties? Any LLM? Since an LLM is not changing, what does "alter the internal logic pathways" mean? As for the approach: Is the following a correct overview description? I am interested in the core of the approach to get rid of misunderstandings (on my part) prepare a text based prompt Send the prompt as input to a software that uses an LLM to generate a response for the prompt. Show the result to the user. In your case the prompt is pretty advanced, by still "only" a prompt. The LLM acts only on the prompt given by the user; there is no interaction with other tools os systems and there's is interactions with other users' sessions. The output is not modified; all output to the user comes from the LLM
-
But that seems to contradict earlier statements and explanations.
-
Chat-based tools currently available to the general public (for instance ChatGPT*) allows selection of a language model (LLM), supplementary tools and integrations, user configuration (including for instance access to chat history or a persistent "memory") and the outcome and usefulness of the interaction is greatly affected by the selections made by the user. The same holds for local installations of for instance open source tools and models. In the context of Prajna's question it makes, as far as I can tell, a difference if the discussion is about mechanisms that change the LLM or not. *) Differences exists depending on market, type of license etc
