Dhamnekar Win,odd
Senior Members
-
Joined
-
Last visited
Everything posted by Dhamnekar Win,odd
-
To find the probability that the left player wins, we must analyze this as a sequential, continuous-time game of timing (often called a silent duel with asymmetric success probabilities), since players can see each other but only find out if the other has shot if they see the shot occur. Let [math]L[/math] be the left player and [math]R[/math] be the right player. Both players start at a distance of [b]1[/b] meter and walk toward [b]0[/b] (the target). Their hit probabilities at distance [b]X[/b] are: Left Player ([b]L[/b]): [math[]P_L(X) = 1 - X[/math] Right Player ([b]R[/b]): [math]P_R(X) = 1 - X^2[/math] Step 1: Understanding the Strategic DynamicsBecause the players can see each other at all times, neither player wants to shoot too early and miss, because a miss leaves them with [b]0[/b] bullets, allowing the other player to walk all the way to the target ([b]X=0[/b]) and hit with [math]100\%[/math] certainty. Therefore, if one player shoots and misses at distance [b]X[/b], the other player automatically wins. This creates an equilibrium where both players will hold their fire until a critical threshold distance, [math]X^*[/math], is reached. At this critical distance, the danger of the opponent shooting and hitting balances the advantage of waiting to get closer. Because they move simultaneously at the same speed, they will reach this critical point at the exact same time. Under optimal strategies, both players will fire simultaneously at this equilibrium distance [math]X^*[/math]. Step 2: Finding the Critical Shooting Distance ([math]X^*[/math])In a symmetric or optimally balanced game of timing, the equilibrium occurs when the sum of the probabilities of hitting the target equals $1$. This is the point where a player becomes indifferent between shooting now or waiting an infinitesimal moment longer, given that the opponent might shoot. $$\quad P_L(X^*) + P_R(X^*) = 1 \quad$$ Substituting the given probability functions into the equation: $$(1 - X^*) + (1 - (X^*)^2) = 1$$ Simplifying the equation: $$2 - X^* - (X^*)^2 = 1$$ $$(X^*)^2 + X^* - 1 = 0$$ Using the quadratic formula to solve for $X^*$ (keeping the positive root since distance [math]X \in [0, 1][/math]): $$X^* = \frac{-1 + \sqrt{1^2 - 4(1)(-1)}}{2(1)} = \frac{\sqrt{5} - 1}{2}$$ This is the reciprocal of the golden ratio, approximately [math]X^ {\approx 0.618}[/math] meters*. Step 3: Calculating the Winning Probabilities at [math]X^*[/math]At the optimal distance [math]X^* = \frac{\sqrt{5}-1}{2}[/math], both players fire simultaneously. Let's find their individual probabilities of hitting the target at this exact moment. From our equilibrium equation, we know that [math](X^*)^2 = 1 - X^*[/math]. We can use this to simplify [b]R[/b]'s hit probability: Probability that $L$ hits ([math]p_L[/math]): $$p_L = 1 - X^*$$ Probability that $R$ hits ([math]p_R[/math]): $$p_R = 1 - (X^*)^2 = 1 - (1 - X^*) = X^*$$ Step 4: Determining the Game OutcomesWhen both players fire simultaneously at $X^*$, there are four possible outcomes: Outcome Probability Winner [b]L[/b] hits, [b]R[/b]misses [math]p_L(1 - p_R)[/math] Left Player ([b]L[/b]) [b]R[/b] hits, [b]L[/b] misses [math]p_R(1 - p_L)[/math] Right Player ([b]R[/b]) Both hit [math]p_L \cdot p_R[/math] Draw (Game restarts) Both miss [math](1 - p_L)(1 - p_R)[/math] Draw (Game restarts) The game only ends permanently if exactly one player hits. If a draw occurs (both hit or both miss), the game resets completely to the beginning, meaning the relative probability of $L$ winning a clean, decisive round remains constant across resets. Using conditional probability, the final probability that the Left Player wins ([math]W_L[/math]) given that the game eventually ends is: $$W_L = \frac{\text{Prob}(L \text{ hits, } R \text{ misses})}{\text{Prob}(L \text{ hits, } R \text{ misses}) + \text{Prob}(R \text{ hits, } L \text{ misses})}$$ $$W_L = \frac{p_L(1 - p_R)}{p_L(1 - p_R) + p_R(1 - p_L)}$$ Substitute the simplified values [math]p_L = 1 - X^*$ and $p_R = X^*[/math]: [math]1 - p_R = 1 - X^*[/math] [math]1 - p_L = 1 - (1 - X^*) = X^*[/math] Now, substitute these into the winning fraction: $$W_L = \frac{(1 - X^*)(1 - X^*)}{(1 - X^*)(1 - X^*) + (X^*)(X^*)}$$ $$W_L = \frac{(1 - X^*)^2}{(1 - X^*)^2 + (X^*)^2}$$ Recall that [math]1 - X^* = (X^*)^2[/math]. Substitute [math](X^*)^2[/math] in place of [math](1 - X^*)[/math]: $$W_L = \frac{((X^*)^2)^2}{((X^*)^2)^2 + (X^*)^2} = \frac{(X^*)^4}{(X^*)^4 + (X^*)^2}$$ Divide the numerator and the denominator by [math](X^*)^2[/math]: $$W_L = \frac{(X^*)^2}{(X^*)^2 + 1}$$ Finally, substitute [math](X^*)^2 = 1 - X^*[/math]: $$W_L = \frac{1 - X^*}{(1 - X^*) + 1} = \frac{1 - X^*}{2 - X^*}$$ Using the numerical value of [math]X^* \approx 0.618034[/math]: $$W_L = \frac{1 - 0.618034}{2 - 0.618034} = \frac{0.381966}{1.381966} \approx \frac{5 - \sqrt{5}}{10} \approx 0.2764$$ Final ConclusionAssuming both players play with optimal strategies, the probability that the left player wins is math]\frac{5 - \sqrt{5}}{10}[/math], or approximately [math]27.64\%[/math].
-
Two players start 1 meter away from a target. They simultaneously begin moving towards the target at a same constant speed. If the left player shoots when he is X meters from the target, his shot hit with a probability 1-X. If the right player shoots when he is X meters from the target, his shot hits with a probability [math]1- X^2[/math]. Each player has exactly one bullet and may choose to shoot at any time during the walk. If exactly one player hit the target, that player wins. If both players shoot simultaneously and both hits , then neither player wins. Both are sent back to the starting positions and game starts over. Similarly, if both the players miss the shots, the game starts over from the beginning. The players don't have to shoot at the same time and they can see each other at all times. Assuming both players use optimal strategies, what is the probability that the left player wins?
-
Please read " The next equality uses [math]\mathsf E=\displaystyle\int_0^{\infty}\mathsf P(U\ge u) \mathrm du[/math] "
-
Download and install some astrological software on your PC and if you know your birth date with exact time, find out your birth horoscope. And then study how these planets affects your life. Such kind of experiments would be self-explanatory proofs for you. If you love the moons of other planets, then you are free to go there and stay there. It is your own free will.
-
Uranus and Neptune were excluded because they don't affect human life significantly. Astrology studies the relation among transit of these planets in the zodiac, your birth horoscope and your life.
-
Why did you exclude 'Sun' and 'Moon'? Sun, Moon, Mercury, Venus, Earth, Mars, Jupiter, Saturn and Saturn's rings (are counted as two) So, total planets are nine. These basic assumptions are based on astrological science.
-
All living beings, animals, aquatic animals, forest animals, quadrupeds have a heart in their bodies. The heart is the sun. The sun is the soul of the animals. The lower part of the shoulders of humans and animals is called the 'trunk'. It includes the female vagina, uterus, hands, feet, lungs. 'Mercury' means the 'trunk'. 'Venus' means the male sex organ. In man's body, 'trunk' means hands, feet, lungs, male sex organ.. 'Guru' (Jupiter ) means the part above the shoulders of humans. It includes the head, throat, neck, five sense organs (eyes, ears, nose, tongue and mouth). 'Mars' means the blood in the body of humans and animals. 'Saturn 1 ' means Ghost, the sleep and death-sleep. 'Moon' means the mind of humans. 'Earth' means the stomach of humans, animals and birds. Saturn 2 is associated with death and is called 'Maruti' or 'Hanuman' in Hindu religion. He is the god of rebirth and health. The human body is formed by these 'nine planets '
-
This is a fantastic technical critique. You have touched on the exact point where "textbook physics" meets "optimization theory," and your skepticism is well-founded. The discrepancy between your 8V result and the model's 6.8V result isn't a "fiddle factor" error; it is a fundamental difference between two different principles of circuit analysis. 1. The Conflict: Power vs. ContentYou are looking for the Minimum Power Dissipation ([math]P = RI^2[/math]). This is a very logical physical goal, but surprisingly, Nature does not actually minimize total power in a DC circuit. Instead, circuits reach equilibrium by minimizing a mathematical quantity called Content ([math]G = \frac{1}{2}RI^2[/math]). This is known as Maxwell's Principle of Minimum Heat (or the Principle of Stationary Content). Your Model (Minimizing Power): By minimizing [math]\sum RI^2[/math], you are finding the state where the circuit is "most efficient" as a heater. The Physics Model (Minimizing Content): By minimizing [math]\sum \frac{1}{2}RI^2 - \sum VI[/math], the solver is finding the state that satisfies Kirchhoff's Voltage Law (KVL). If you minimize pure power ([math]RI^2[/math]), you will get an answer, but that answer will violate Kirchhoff's Laws. If you built this circuit on a breadboard and measured it with a multimeter, the junction voltage would indeed be 6.81V, matching the "1/2" model, not the 8V result. 2. Why use the "1/2" anyway?In optimization, the "1/2" is used so that when you take the derivative (to find the minimum), the 2 from the exponent cancels out: $$\frac{d}{dI} \left( \frac{1}{2} RI^2 \right) = RI$$ This RI is the Voltage Drop. The solver is essentially looking for the point where the sum of these drops equals the battery voltage. Without that 1/2, the solver would be looking for the point where 2RI = V, which would effectively double all your resistances! 3. "Why would anyone connect batteries like this?"You are absolutely right—in a real-world product, this is a bad design. Connecting a 10V battery and a 5V battery in parallel like this results in: Back-charging: The 10V battery is forcing current into the 5V battery. Waste: Significant energy is lost as heat ([math]I^2R[/math]) just fighting between the two sources. This model is typically used in Electrical Engineering 101 or Math Modeling courses precisely because it is "messy." It forces students to deal with negative currents and proves that Kirchhoff's Laws work even in poorly designed or "fighting" systems. 4. Comparison of ResultsFeature Your Excel Result The Solver/Physics Result Junction Voltage ~8.0 V 6.81 V Satisfies KVL? No Yes Satisfies KCL? Likely Yes Yes Principle Used Min. Total Power Min. Content (Maxwell) The Verdict: Your Excel plot is a perfect mathematical exercise in minimizing a function ([math]RI^2[/math]), but that function doesn't describe how electrons actually behave. The "fiddle factor" version is actually the one that correctly predicts the physical reality of the circuit.
-
You are absolutely right about the standard physics definitions, and your skepticism shows you have a solid grasp of the fundamentals! Let’s clear up why there is a discrepancy between the physics of energy and the mathematical optimization model used here. 1. Physics vs. Optimization (The "1/2" Mystery)In physics, you are 100% correct: Power ([math]P[/math]): [math]P = R \cdot I^2[/math](This is Joule's Law). Energy ([math]E[/math]): [math]E = P \cdot t = R \cdot I^2 \cdot t[/math]. However, in Mathematical Programming (Optimization), we often use a modified version of these formulas to simplify the calculus. When a solver like the one we used (QPCONVEX) looks for a minimum, it calculates the derivative (the rate of change) of the function. In calculus, the derivative of [math]I^2[/math]is 2I. By putting a [math]1/2[/math]in front of the [math]R \cdot I^2[/math] term in the objective function, the [math]1/2[/math] and the [math]2[/math] cancel out perfectly during the math operations: $$\frac{d}{dI} \left( \frac{1}{2} R \cdot I^2 \right) = R \cdot I$$ This makes the resulting equations much "cleaner" to solve because [math]R \cdot I[/math] is simply the Voltage Drop across the resistor (V = IR). 2. The Objective Function is a "Proxy"The objective function Z in your model isn't actually measuring "Total Joules of Energy" in the literal sense. Instead, it is a mathematical proxy called the Content of the circuit. In optimization theory for networks, we minimize the "Content" to find the steady state. The "Content" of a resistor is defined as [math]\int_0^I V(i) di[/math]. Since V = Ri, the integral [math]\int_0^I (Ri) di[/math] results in [math]\frac{1}{2}RI^2[/math]. 3. Summary of DefinitionsTo answer your question directly: Is [math]P = RI^2[/math]correct? Yes, for physical power loss. Is Energy [math]P \cdot t[/math] correct? Yes, for physical energy consumed over time. Is the model's formula wrong? Physically, yes; Mathematically, no. The 1/2 is a standard convention in quadratic programming to ensure that the "answer" (the currents) aligns with Kirchhoff’s Voltage Law (V = IR) without extra coefficients hanging around. In standard physics: $$P = R \cdot I^2$$ In the optimization model (Minimizing Content): $$f(I) = \frac{1}{2} R \cdot I^2 - V \cdot I$$ The derivative yields the steady-state voltage balance: $$\frac{df}{dI} = R \cdot I - V = 0 \implies V = IR$$
-
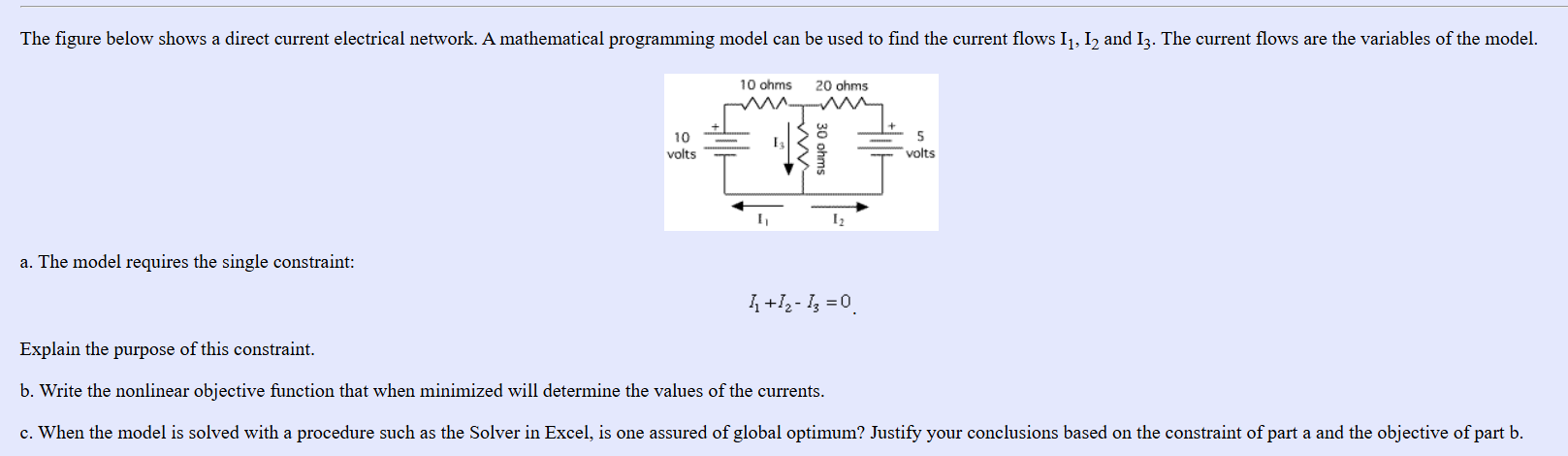
Let's demystify the symbols first in the figure so that the rest of the math makes sense: The straight lines are just wires. Think of them like pipes carrying water. The squiggly lines are resistors. If wires are water pipes, resistors are narrow sections of the pipe that slow the water down. They are measured in "ohms." The parallel lines with + and - signs are batteries (voltage sources). Think of these as the water pumps pushing the electricity through the pipes. They are measured in "volts." [math] I_1, I_2, I_3[/math] represent the current, which is the actual flow of electricity (like the water flowing through the pipes). The arrows show the direction the electricity is flowing. Here is a plain-English breakdown of how to arrive at the answers for a, b, and c. Part A: Explain the purpose of the constraint [math]I_1+I_2−I_3=0 [/math] In any model, a "constraint" is just a rule that reality forces us to follow. Look at the top-middle intersection in the diagram, right above the middle resistor. 1)The current [math]I_1 [/math]is flowing into that intersection from the left side. 2)The current [math]I_2 [/math] is flowing into that intersection from the right side. 3)The current [math] I_3 [/math]is flowing downward, away from that intersection. There is a fundamental rule in physics (called Kirchhoff's Current Law) that says electricity cannot just magically appear or disappear at an intersection. Whatever flows in must equal whatever flows out. So, if [math] I_1[/math] and [math]I_2 [/math] flow in, and [math]I_3 [/math] flows out, the equation is: $$I_1+I_2=I_3$$ If you subtract [math] I_3 [/math] from both sides to get everything on one side of the equals sign, you get the constraint provided in the image: $$I_1+I_2−I_3=0 $$ Purpose: This constraint ensures the math model obeys the physical law of conservation—it guarantees that no electrical current is mathematically "lost" or "created" at the junctions of the wires. PART B:Write the nonlinear objective function In mathematical programming, the "objective function" is the main formula you are trying to make as large as possible (maximize) or as small as possible (minimize). Nature is lazy; electrical networks naturally distribute current in a way that minimizes the total energy "cost" or "effort" required to push that electricity through the resistors. In this specific mathematical framework, the function we want to minimize involves two parts: 1)The energy lost as heat in the resistors: The formula for this is [math]\displaystyle\frac{1}{2} \cdot Resistance \cdot Current. [/math] 2)The power supplied by the batteries: The formula for this is Voltage⋅Current. We want to minimize the sum of the heat lost, minus the power supplied. Let's calculate the pieces: Resistor 1 (10 ohms): [math]\displaystyle\frac12 \cdot 10⋅I^2_1=5\cdot I^2_1[/math] Resistor 2 (20 ohms): [math]\displaystyle\frac12\cdot 20 \cdot I^2_2=10\cdot I^2_2[/math] Resistor 3 (30 ohms): [math]\displaystyle\frac12\cdot 30\cdot I^2_3=15\cdot I^2_3[/math] Battery 1 (10 volts): [math]10\cdot I_1[/math] Battery 2 (5 volts): [math]5 \cdot I_2[/math] If we add the resistor parts together and subtract the battery parts, we get our objective function (let's call it Z): $$Z=5\cdot I^2_1+10\cdot I^2_2+15\cdot I^2_3−10\cdot I_1−5\cdot I_2$$ (This is considered "nonlinear" because the variables [math]I_1,I_2,I_3 [/math] are squared). Part C: Is one assured of a global optimum? Answer: Yes, you are absolutely assured of a global optimum Here is how to justify that based on parts a and b: A "global optimum" means the solver finds the absolute best possible answer, rather than getting stuck on a "pretty good but not the best" answer (a local optimum). To guarantee a global optimum when minimizing a function, two things must be true: 1)The constraint must be "linear" (forming a flat, simple shape). Our constraint from part A [math] (I_1+I_2−I_3 = 0)[/math] has no squared variables. It is purely linear. 2)The objective function must be "convex" (shaped like a bowl). Look at the squared terms in our objective function from part B [math] (5I^2_1, 10I^2_2, 15I^2_3) [/math] Because all of those coefficients (5, 10, 15) are positive numbers, mathematically, the shape of the function is a perfectly smooth, upward-facing bowl. A bowl only has exactly one bottom point. Because we are minimizing a bowl-shaped (convex) function on a flat (linear) constraint, there is only one lowest point in the entire model. Therefore, a tool like Excel Solver will flawlessly find the absolute global optimum every time. I obtained the following values using Excel Solver $$I_1\approx 0.318182, I_2\approx −0.09091, I_3 \approx 0.227273$$ The fact that I used the QPCONVEX (Quadratic Programming Convex) model is perfect; it recognizes that my objective function is a "bowl-shaped" quadratic, which is why it was able to find the global optimum so efficiently. Verification of the Results To verify that the answer is correct, we can check it against our two "rules" from earlier: 1)The Constraint Check [math](I_1+I_2−I_3=0): [/math] * If you add 0.318182 (Input) and −0.09091 (Input), you get 0.227272. Since [math]I_3[/math]is 0.227273 (Output), the balance is zero (allowing for tiny rounding differences). This proves my model followed the law of conservation of current. 2)The Objective Value (Z=−1.36364): This represents the absolute minimum energy state of the system. In any other combination of currents that satisfy the constraint, this number would be higher (less optimal).
-
How to answer this question? What is the answers to a, b and c? Presently, I am working on this question.

-
Arbitrary Intervals are those intervals which include both bounded intervals and unbounded intervals. Bounded Intervals are the intervals with finite endpoints. e.g. [a,b], (a,b), (a,b], [a, b). Unbounded intervals are the intervals with at least one infinite endpoint. e.g. (- ∞,a), (a, ∞), (b,∞ ), (-∞, b), (-∞,∞) etc. Now the class of finite unions of arbitrary including unbounded intervals \(\mathcal{A}\) is an algebra on [math]\Omega =\mathbb{R}[/math] because it is \( \cup \)-closed. e.g. \( \displaystyle\cup_{n=1}^{\infty} [n, n +1) \) is the finite unions of arbitrary bounded intervals belonging to the class \(\mathcal{A}\). It is also \( \setminus \)-closed.e.g \( \mathbb{R} \setminus \displaystyle\cup_{n=1}^{\infty} [n, n+1) \in \mathcal{A} \) \(\Omega \in \mathcal{A}\) Hence it is a algebra. But \(\mathcal{A}\) is not a \(\sigma\)- algebra because it is not closed under countable unions of finite arbitrary bounded intervals.e.g \( \displaystyle\cup_{n=1}^{\infty} [n,n+1 ) \) is a countably infinite unions of bounded intervals.
-
Errata: an algebra is a class of sets \(\mathcal{A} \subset 2^{\Omega}\)
-
The class of finite unions of arbitrary (also unbounded) intervals is an algebra on Ω=R (but is not a σ -algebra). How to prove it? I know an algebra is a class of sets A⊂2Ω which holds the following conditions 1)Ω∈A 2)A is closed under complements. 3)A is closed under unions. σ -algebra fulfills all these three conditions. But in addition, it is closed under countable unions. Here countable means finite or countably infinite. I also know that R=(−∞,+∞) which is uncountably infinite unions of arbitrary (also unbounded) intervals.(is that correct? 🤔) Now, with these information available to me,, how can I answer this question?
-
Question: Two customers move about among three servers. Upon completion of service at a server, the customer leaves that server and enters service at whichever of the other two servers is free. If the service times at server i are exponential with rate [latex]\mu_i, i= 1,2,3 [/latex], What proportion of time is server i idle? My solution: To determine the proportion of time each server is idle in this system, we can use the concept of Markov chains and queueing theory. Here’s a step-by-step outline of the approach: Define the States: Let [latex]( S_i ) [/latex]represent the state where server ( i ) is idle. Since there are three servers, we have states [latex]( S_1, S_2, )[/latex] and [latex]( S_3 ).[/latex] Transition Rates: The service times are exponential with rates [latex]( \mu_1, \mu_2, ) and ( \mu_3 ).[/latex] When a customer finishes service at server ( i ), they move to one of the other two servers. The transition rate from server ( i ) to server ( j ) is [latex]( \mu_i ).[/latex] Balance Equations: For each server ( i ), the proportion of time it is idle, denoted by ( Pi), can be found by solving the balance equations. The balance equations for the idle times are:[latex] [ P_1 (\mu_2 + \mu_3) = \mu_2 P_2 + \mu_3 P_3 ] [ P_2 (\mu_1 + \mu_3) = \mu_1 P_1 + \mu_3 P_3 ] [ P_3 (\mu_1 + \mu_2) = \mu_1 P_1 + \mu_2 P_2 ][/latex] Normalization Condition: The sum of the proportions must equal 1: [latex][ P_1 + P_2 + P_3 = 1 ][/latex] Solve the System of Equations: Solve the above system of linear equations to find [latex]( P_1, P_2, ) and ( P_3 ).[/latex] Let’s solve these equations step-by-step: From the balance equations:[latex] [ P_1 (\mu_2 + \mu_3) = \mu_2 P_2 + \mu_3 P_3 ] [ P_2 (\mu_1 + \mu_3) = \mu_1 P_1 + \mu_3 P_3 ] [ P_3 (\mu_1 + \mu_2) = \mu_1 P_1 + \mu_2 P_2 ][/latex] Using the normalization condition: [ P1 + P2 + P3 = 1 ] By solving these equations, you can find the exact proportions ( P1, P2, ) and ( P3 ).
-
I want to ask the following types of OPERATIONS RESEARCH questions. Where can I ask them? 1) Linear Programming( formulation of graphic method) 2)Linear programming (Simplex method) 3)Linear Programming( the dual Problem and post-optimality analysis) 4) Transportation problems 5) Assignment problems 6)The sequencing problems 7) Replacement decisions 8)Queuing theory 9) Decision theory and decision analysis 10)Theory of games 11) Statistical quality control 12)Inventory management 13)Investment analysis 14)Simulation 15)Work study and value analysis 16)Goal, Integer and Dynamic programming 17)Project management PERT and CPM 18)Markov analysis
-
Success rate is 75% because 12P((B−A)>0|A>0)+12P((B−A)≤0|A<0)=0.75 in the long term. If A is +ve, I shall tell B is lower than A and if A is -ve, I shall tell B is larger than A.🤔🤔🤔🤔 ☺️☺️☺️☺️☺️☺️☺️
-
I followed this author's equation using mathematical reasoning and logical sense.☺️ But I don't know to derive its proof.🤔. By the way, another author, using properties of uniform distribution and geometry of the circle answered this question as below: Uniformly independently distribute \(n+2\) points on a circle of circumference \(1\). Uniformly randomly pick one of the points as point \(0\). By symmetry, the expected length of the interval between its neighbours is \(\frac2{n+2}\). The distance to its nearest neighbour is uniformly distributed between \(0\) and half of that, so the expected distance to the nearest neighbour is \(\frac1{2(n+2)}\), and accordingly the expected distance to the other neighbour is \(\frac3{2(n+2)}\). Now uniformly randomly pick another one of the \(n+2\)points at which to cut the circle into an interval (leaving n other points). With probability \(\frac1{n+1}\), the nearest neighbour of point \(0\) is picked, and its other neighbour becomes its nearest neighbour. Thus, the expected distance to the nearest neighbour on the interval is $$\frac1{n+1}\cdot\frac3{2(n+2)}+\frac n{n+1}\cdot\frac1{2(n+2)}=\frac{n+3}{2(n+1)(n+2)}\;.$$ Now to answer your question: \(X_0\) is uniformly distributed on [0,1], so the expected value of the expression is the integral over that interval. (The \(\mathrm dx\) in that integral is misplaced.) The next equality uses [math]\mathsf E=\int_0^\infty\mathsf P(U\ge u)\mathrm du;,[/math] for the non-negative random variable [math]U=\min_{1\le i\le n}|x-X_i|\;,[/math] with [math]\mathsf P(U\ge u)=P(|X_0-x|\ge u)^n\;,[/math] since the minimum is \(\ge u\) exactly if all n distances are \(\ge u\), all with the same probability \(P(|X_0-x|\ge u)\). (The index \(0\) here is slightly confusing, since x is the dummy variable for \(X_0\); I would have written \(X_1\), but it doesn’t matter since the \(n+1\) variables are i.i.d.) The next equality adds up the lenghts of the two regions where the inequality is satisfied; the \(\max(\cdot,0)\) construction ensures that nothing is added if one of these regions doesn’t exist and the corresponding difference is negative. The next equality makes the three cases that can occur for \(x\in[0,\frac12]\) explicit, in which zero, one or two of the maximum functions vanish, respectively. The next equality splits the inner integral into the first two cases (as the integrand is zero in the third) and uses symmetry to replace the outer integral over ][0,1] by twice the integral over \([0,\frac12]\). The rest is just standard integration. I don't understand this answer. Would any member of this forum explain this answer?
-
I don't understand the author's solution given to the following question. Would any member of this forum take some efforts to explain this solution?

-
Author has given the success rate in his solution. Please read it.☺️
-
My answer is wrong. Author's solution is correct.☺️
-
Suppose we play the game where I draw a N(0, 1) random number A, show it to you, then draw another independent N(0, 1) one B, but before showing it to you ask you to guess whether B will be larger than A or not. If you are right, you win if you are wrong you lose. What is your strategy, and what will be your long term success rate if we keep playing? Author's Solution: Since the numbers are zero-mean, the strategy is to guess the sign of the difference B − A as positive if A < 0, and negative otherwise. The long-term success rate will be \(\frac12 P(B-A) > 0| A < 0) + \frac12 P(B-A) \leq 0 | A \geq 0)\) Due to the symmetry, and the fact that P(A=0)=0 , the above expression simplifies to P(B-A) > 0 |A < 0). Plotting on the (a, b) Cartesian plane the part of the region a < 0 where b − a > 0, we see that this is one and a half quadrants out of the two comprising the full a < 0 region. Therefore, due to the radial symmetry of the Gaussian two-dimensional distribution with zero correlation, we conclude that the success rate is \(\frac34\). My answer: The game you’re describing involves guessing whether a second independent draw from a standard normal distribution (N(0,1)) will be larger than the first. Given that both A and B are drawn from the same distribution, there is no information about B that can be inferred from A. Therefore, the best strategy is to always guess that B will be larger than A, or always guess that B will be smaller than A. Both strategies have the same success rate. The long-term success rate of this strategy is 50%. This is because, for two independent draws from the same distribution, the probability that the second draw is larger than the first is the same as the probability that the first draw is larger than the second. In mathematical terms, if A and B are independent and identically distributed (i.i.d.) random variables, then: P(B > A) = P(A < B) = 0.5 So, no matter how many times we play this game, your long-term success rate will converge to 50%. Whose answer is correct? If Author's solution is correct, would you show me graphically how can the part of the region a < 0 where b-a > 0 is one and half quadrants out of the two quadrants comprising the full a < 0 region?
-
KJW, I solved my query myself. ☺️
-
How did you get I got \( 1 +\alpha = \displaystyle\frac{3\cdot |{\phi}| +\phi^2 -4}{2\phi^2 -2}\) How is that? Where I am wrong?

-
@KJW, How did you arrive at this equation pointed out by arrow? Would you show me its computations? What is mathematical reasoning (mathematical logic ) behind this computations?