The Mule
-
Posts
6 -
Joined
-
Last visited
-
Days Won
1
The Mule's Achievements
Lepton (1/13)
7
Reputation
-

Unsupervised Learning and Neural Architecture Search (NAS)
The Mule replied to The Mule's topic in Computer Science
@Ghideon and @Dagl1, thank you both for your input and ears. My intent for this thread now, seeing as it has gained some traction and as I have a small audience of two, is to lay out what I can figure out on my own and, through this process, more precisely hone in the nature of my mental shortcomings pertaining to this task. Hopefully, the process of documenting my progress with this reproduction will be informative and potentially useful to people who are also uncertain about how to proceed in such things. As @Dagl1 mentions, I want to avoid unnecessarily calling upon others to hold my hand along the way and, quite frankly, I need to learn how to do this sort of thing myself. I think that later tonight I will begin by presenting an overview of some pieces of the research. In addition, I may provide a tutorial-like explanation of how to use Google Cloud. Learning how to use this service is probably the first step since unlike Google Colaboratory, which can stop at any point and is not too robust, the Cloud affords great precision and a wide array of services to understand the machine learning jobs people run through it. Thank you for listening thus far and I look forward to detailing further developments as they come. -
In fact, the Python code that I inserted above is quite different from the methods employed in the paper. The code I added was a very rudimentary presentation of what the structure of something written using Keras may appear like. Nonetheless, I agree with @Ghideon that @zak100 should attempt to piece together which major components of Keras correspond to the methods used in the paper. As an example, if the paper mentioned a Convolutional Neural Network, then two appropriate answers would be to look at (1) Google search: keras layers -> https://keras.io/api/layers/ -> look at convolutional layers (WHAT IT LOOKS LIKE ON THE WEBSITE) or (2) keras CNN tutorial -> https://victorzhou.com/blog/keras-cnn-tutorial/

-
Hello @zak100, I think a more important step to take before assembling 100,000 instances of data is bench-marking the performance of some baseline or prototype model that you can train on smaller datasets. Once the major limitation becomes how much data you have, then I would consider the problem of getting a ton of data to be your first priority. However, at the moment, I would think it is more crucial for you to read the articles that me and @Ghideon have discussed. With regard to me assisting you through this process, I meant that I can provide a simple model for you in Keras, not a model for SC vulnerability detection, but rather one to just minimally acquaint you with Keras. Thank you @Ghideon showing me the way to write code on here. Here is the general model pipeline in Keras: 1. Create the instance of your model 2. Compile the model 3. Fit your data to the model 4. Evaluate your model's performance 5. Predict new batches of data or datasets using the saved model weights # Example from some project I did. # data = a pandas dataframe with features from a import pandas as pd import tensorflow as tf import numpy as np import itertools as it import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.linear_model import ElasticNet from sklearn.linear_model import Lasso from sklearn.linear_model import SGDRegressor from sklearn.preprocessing import normalize from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error from tensorflow import keras from tensorflow.keras import layers # the 'target' is what you want to predict # since you do not have the data I used here, this code will not actually do anything when ran, # it purely for illustrative purposes only target = data.pop('Wattage') data = MinMaxScaler().fit_transform(data.values).reshape(len(data),5) # your data would go in the inn dataset = tf.data.Dataset.from_tensor_slices((data[:,:4], data[:,-1].reshape(-1,1))) # create the training, testing, and validation datasets train_size = int(len(data)*0.7) test_size = int(len(data)*0.15) train_dataset = dataset.take(train_size) test_dataset = dataset.skip(train_size) val_dataset = test_dataset.skip(test_size) test_dataset = test_dataset.take(test_size) # THIS IS THE IMPORTANT PART, FOR BUILDING A MODEL # a keras Sequential model with three dense layers, the last being the output layer # in this case we put a '1' for the 'units' parameter because we are predicting one target model = keras.Sequential( [ layers.Dense(units=32, activation='relu', name='layer1'), layers.Dense(units=64, activation='relu', name='layer2'), layers.Dense(units=1, name='end'), ] ) # compile the model with the correct optimizer, loss, and metrics model.compile( optimizer='adam', loss='mse',#tf.keras.losses.MeanSquaredError(reduction="auto", name="mean_squared_error"), metrics=['mse'] ) # fit your model to the training dataset and specify the validation dataset model.fit( x=train_dataset, epochs=20, validation_data=val_dataset, verbose=1, callbacks=[tf.keras.callbacks.EarlyStopping(patience=5)], shuffle=False, ) # evaluate the model's performance model.evaluate( x=test_dataset, verbose=1, callbacks=[tf.keras.callbacks.EarlyStopping(patience=5)], ) # save model for future use, so you do not have to retrain it model.save( filepath='/tmp/trained_on_cleaned_02', )
-
Hello zak100, I think I can help you with the implementation of statistical models for what you want, for "Smart Contract (SC) related vulnerability detection". However, before I do this, I am going to need you to describe more about smart contract vulnerability detection. What exactly is this? A machine learning pipeline, or more generally, a modeling pipeline, begins you assembling or locating a dataset that captures the information you desire to use. So, do you know of any datasets with the vulnerability levels of smart contracts quantified? Next, you'd proceed by implementing or employing a statistical model. In this case, if the vulnerability levels are on a scale of 1-10 or something like this, we'd use a multi-class classification model, and if they are regressive, meaning that if they are some float value like 12.3 or 69.87, we'd use a regression model. In the case that the data are a time series, we then might employ an LSTM. Remember that Neural Networks are not always necessary and may even be unoptimal if we don't have that much data. Once we have our model, we can adjust and fine-tune it to produce the best results while not overfitting, which is when the model learns the dataset it was given too well and reduces how well it generalizes, or phrased differently, how well it performs on new datasets. Using Google search, I have come across this website: https://smartbugs.github.io/ It has listed several Smart Contract datasets, although I am uncertain if these are the type you are searching for. There are also research papers that came up, such https://www.ijcai.org/Proceedings/2020/0454.pdf and https://alfagroup.csail.mit.edu/sites/default/files/documents/2020. Exploring Deep Learning Models for Vulnerabilities Detection in Smart Contracts.NLeSimple-Master_Thesis.pdf . These might have code to them that you can use. If you search on https://paperswithcode.com/ for "smart contract vulnerabilities" I am hopeful that a few papers would come up. Perhaps you can clone their repositories and play around with their code. I mean, if what you are looking to do already exists, then there is little more efficient that simply using the existing implementation, unless you are trying to reinvent the wheel, which does not seem to be the case here. A good resources for learning about CNN's from a mathematical standpoint is https://cs.nju.edu.cn/wujx/paper/CNN.pdf and for LSTM's is https://colah.github.io/posts/2015-08-Understanding-LSTMs/ . I do admit that I have not read these yet in full and absorbed their significance. Scikit-Learn and Keras would probably be good for you for ML implementation in Python. Also, how do I write a code block on this website? Once I learn the answer to the above question I will write a simply keras model in Python for you to see.
-
The Mule changed their profile photo
-
Hello Everyone, Is there anyone here reading X-Risk and, if so, would you like to discuss it over Discord or Zoom or DMs sometime? Later I will include some of my favorite quotes or pieces of information that I liked about it in this thread and maybe some of you will enjoy them too. X-Risk: https://www.amazon.com/X-Risk-How-Humanity-Discovered-Extinction/dp/1913029840/ref=sr_1_1?dchild=1&keywords=X-Risk&qid=1608068155&sr=8-1

-
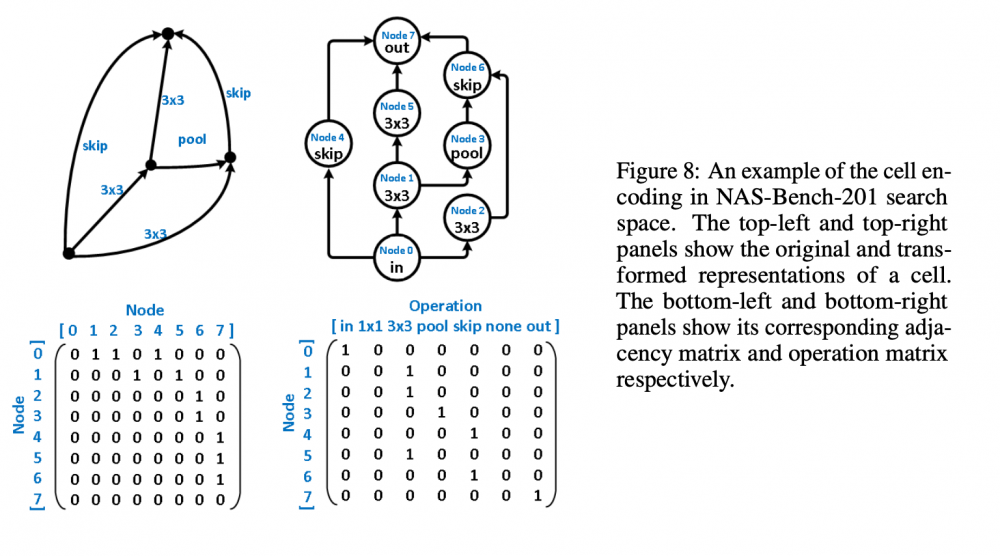
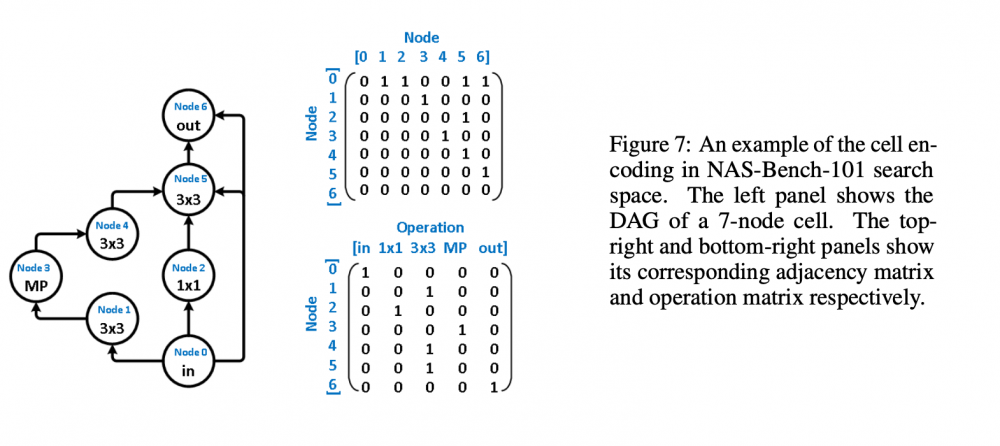
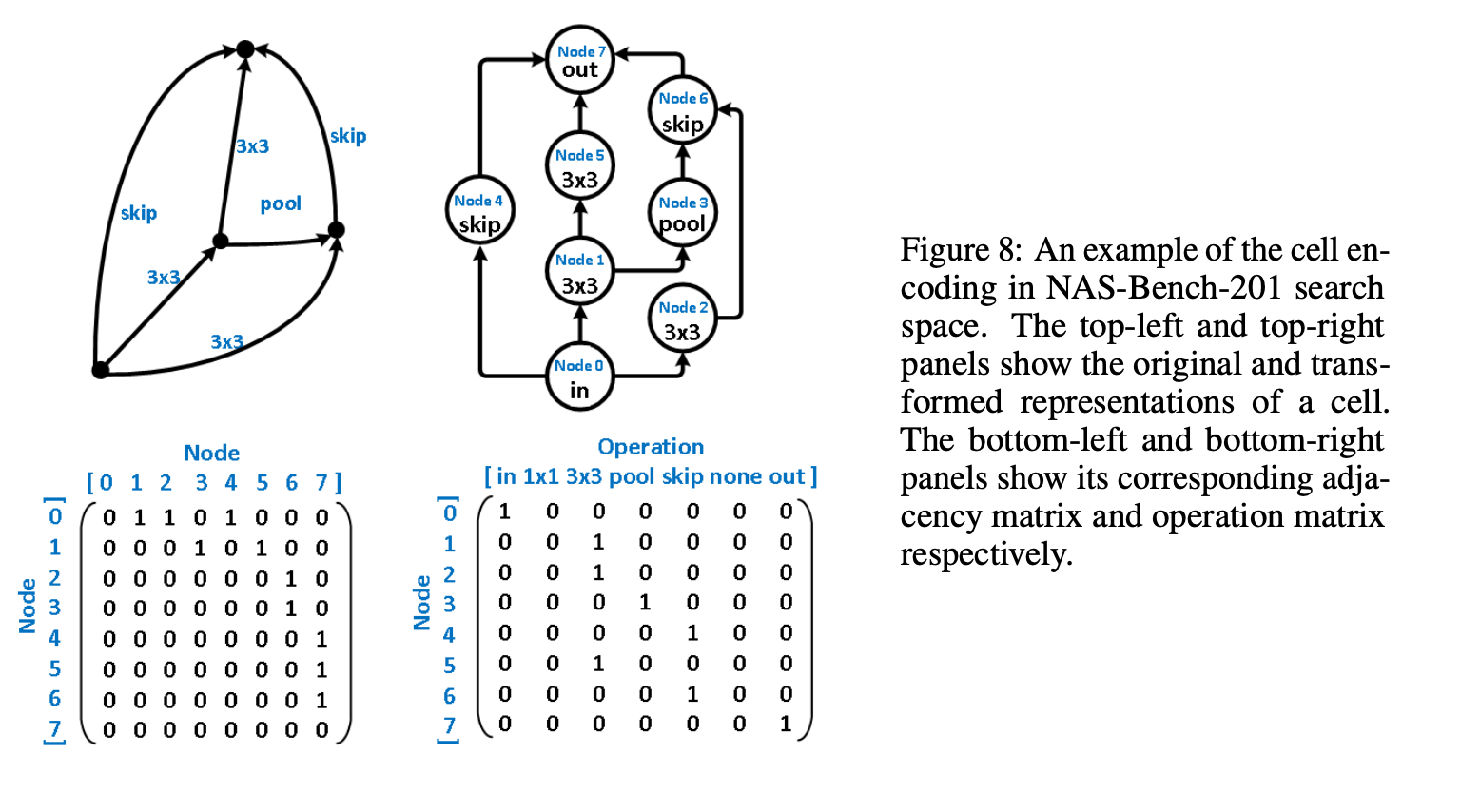
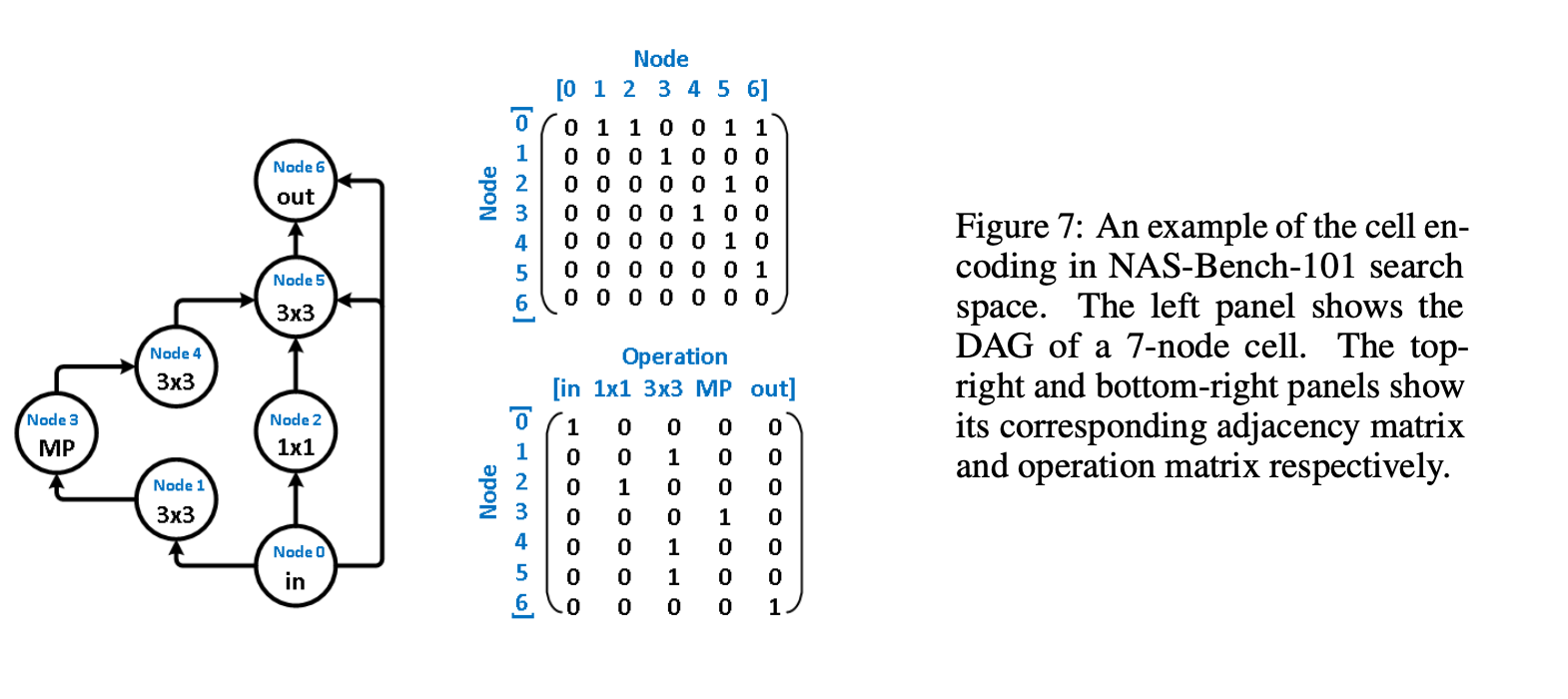
Greetings everyone, I am new to this forum and am excited as such. Another forum that I frequent - The Fossil Forum - seems to adopt the same the software or platform as this one; it's familiarity I find comforting alongside the fact that there are, supposedly, many people interested in science here. Now for the what I am creating this post for. My topic here concerns a paper I am trying to reproduce for a challenge. I have about a month remaining before I need to finish my reproduction and am a ways off from having achieved a solid foundation from which I can begin running the tests I need to run. The paper - https://arxiv.org/pdf/2006.06936v1.pdf - I am trying to reproduce is Does Unsupervised Learning Architecture Representation Help Neural Architecture Search? and employs a method of pre-trained embeddings, as opposed to supervised embeddings, to cluster the latent search space in such a way as to slightly increase the efficiency of the search algorithms used later on (this is all under the umbrella or context of Neural Architecture Search). In the author's words, "To achieve this, arch2vec uses a variational graph isomorphism autoencoder to learn architecture representations using only neural architectures without their accuracies. As such, it injectively captures the local structural information of neural architectures and makes architectures with similar structures (measured by edit distance) cluster better and distribute more smoothly in the latent space, which facilitates the downstream architecture search." I have had many troubles thus far in tackling this reproduction: my understanding of the mathematics, my ability to use Google Cloud's computing services, my creativity in devising tests of robustness, and my judgment in selecting which parts of their code base https://github.com/MSU-MLSys-Lab/arch2vec to port from their implementation in PyTorch to TensorFlow. Also, if I do everything I need to, I still have to write it up in a scholarly fashion, which I do not think will be too difficult, but which I think will require much editing and my available time is but a month. So, I come to you today to take a look at one of these troubles, my understanding of the mathematics. I will introduce the first part of their paper that I think is important, the Variational Graph Isomorphism Autoencoder. I think that before I do this, a recap of Neural Architecture Search (NAS) is due (I am certainly not qualified to introduce this but will do the best I can with the knowledge available to me). In NAS, the goal is to generate and/or find the best neural architecture for a particular dataset. There is also the goal of searching for the best performing architecture amongst a dataset of architectures. All this involves many steps. First, a neural architecture must be represented in some way. How would you naturally break down a CNN? Well, researchers use these graph cells which have nodes consisting of operations and edges that connect nodes to one another. The operations can be something such as a 3x3 convolution or 3x3 max-pooling. A single architecture consists of some number of these nodes (it depends on the particular datasets of architecture, with the two important ones in the paper NAS-Bench 101 and NAS-Bench 201). From the former dataset, here is a representation: And from the latter dataset Mathematically, the "node by node" matrix is the upper triangular adjacency matrix \(\mathbf{A} \in \mathbb{R}^{N x N}\) and the "node by operation" matrix can be represented by a one-hot operation matrix \(X \in \mathbb{R}^{N x K} \) where is \(N\) is the number of nodes and \(K\) is a set of predefined operations (remember like a 3x3 convolution). One thing this group of researchers does is augment the adjacency matrix -> \(\tilde{\mathbf{A}} = \mathbf{A} + \mathbf{A}^T\) to allow for bidirectional information flow, to "transfer original directed graphs into undirected graphs". I do not really understand this and would appreciate a contextual description of un/directed graphs in context of isomorphisms. Moving on, the rest of NAS consists of developing some embeddings that a search algorithm (random search, the reinforcement learning REINFORCE algorithm, bayesian optimization) can use to find the best performing architectures in the architecture datasets. The researchers here use a Variational Graph Isomorphism Encoder: Which I am having some trouble mentally turning in TensorFlow code. I feel somewhat lost now, but will probably return to this post with a more strategic mindset in a little bit. For now, are there any resources on graph theory, graph isomorphism autoencoders, autoencoders, that you think would benefit me? Alternatively, does anyone have a broad scoping explanation for the intuition behind graph isomorphism autoencoders and for why they are used here instead of some other method? Thanks to everyone reading this and I hope I can find interesting things to contribute in the future, hopefully in a less verbose manner. Have a nice day and stay safe!